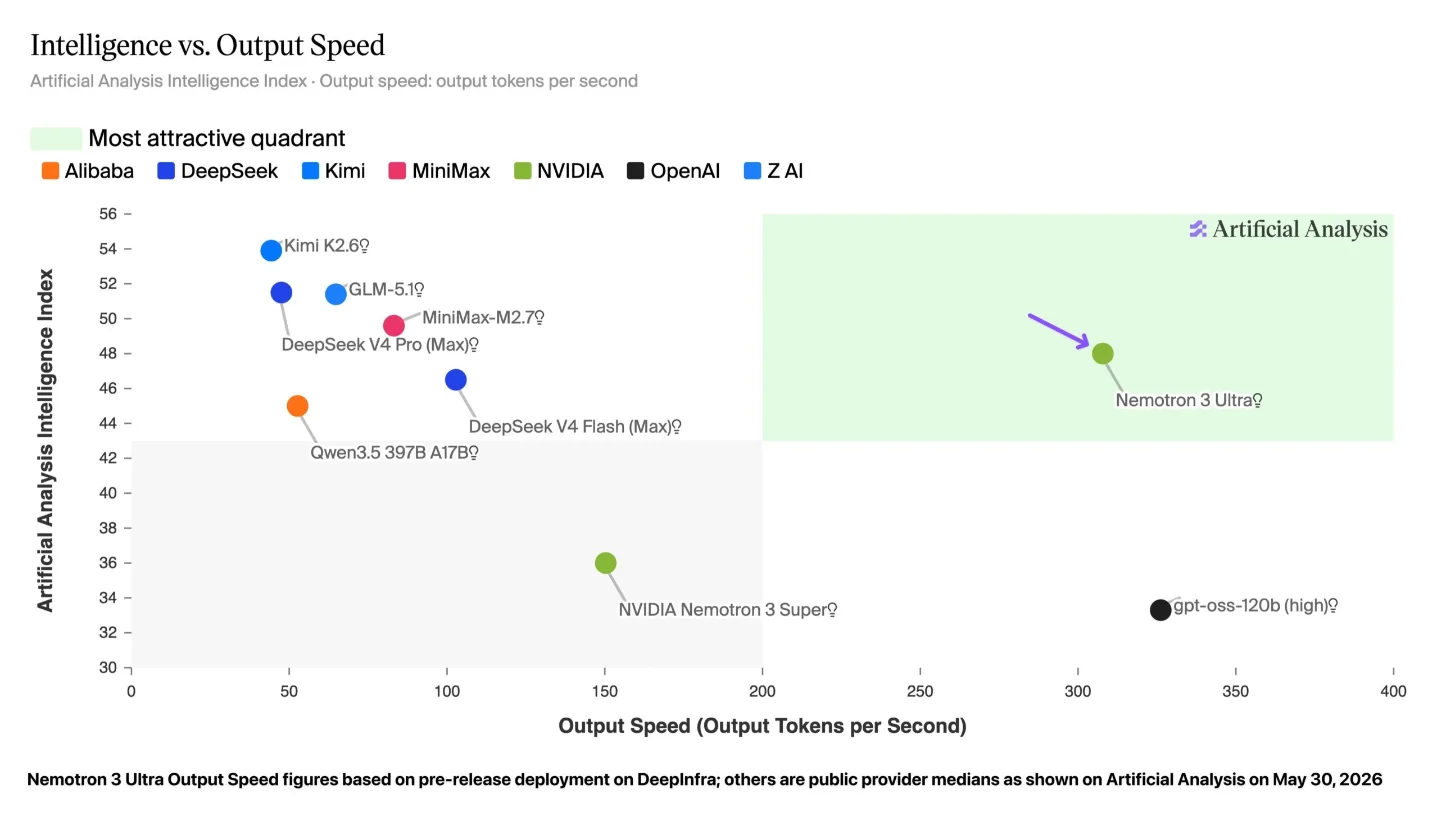
At Computex 2026, Jensen Huang made one argument roughly forty times: "Agentic AI is here, it works, it makes money, and every token is now a revenue unit." 1 The model behind that argument shipped on June 4 — Nemotron 3 Ultra, a 550B-parameter Mixture-of-Experts (MoE) open model that delivers over 400 tokens per second at frontier-class accuracy, up to 5× faster than comparable open frontier models per NVIDIA's official benchmarks. 23 For PMs, the number that matters isn't the parameter count. It's that Nemotron 3 Ultra sits alone in the top-right quadrant of Artificial Analysis's intelligence-versus-speed chart — smarter than every other fast model, faster than every other smart one.
The problem Nemotron 3 Ultra is designed to solve
Long-running agents are economically impractical with today's model stack. A coding agent working through a multi-file refactor makes dozens of sequential tool calls. A research agent synthesizing 200 sources branches into parallel tracks, each requiring reasoning across 100K-token contexts. With a frontier proprietary model generating 40–80 tokens per second, a 100-turn agent run at 1,000 tokens per turn takes several minutes of wall-clock time and a substantial API bill. That latency kills the user experience and makes cost-of-goods unpredictable.
The bottleneck is architectural: standard dense Transformer models pay full quadratic attention cost on every token in the context. Scale the model up for quality, and throughput drops. Scale for throughput, and quality suffers. Most open models with comparable accuracy to frontier proprietary models — Kimi K2.6, GLM-5.1, DeepSeek V4 Pro — top out at 50–100 tokens per second as deployed. 3
How the hybrid Mamba-Attention-MoE architecture breaks the tradeoff
Nemotron 3 Ultra uses a hybrid Mamba-2 + Attention + LatentMoE architecture across 108 layers. 4 The design logic is direct: Mamba-2 layers handle the bulk of long-sequence processing at linear (O(n)) complexity, slashing KV-cache pressure. Sparse Attention layers (just 2 KV-heads against 64 query-heads) appear periodically to maintain precise fact recall when an agent needs to pinpoint a specific reference in a long context. LatentMoE routes each token through 22 of 512 experts per layer, keeping only 55 billion of the 550 billion parameters active at any moment. 4
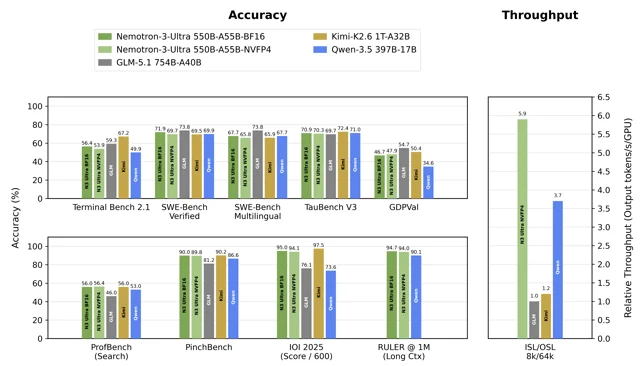
The result: the technical report claims up to ~6× higher inference throughput versus comparable open models while maintaining on-par accuracy. 4 Third-party pre-release measurement put throughput at 5.9× over GLM-5.1 and 4.8× over Kimi-K2.6 on a standardized 8K input / 64K output token workload. 4
NVIDIA official benchmark summary: accuracy across agentic, coding, reasoning, and long-context evals (left panels) plus relative throughput vs. GLM-5.1 and Qwen3.5 (right panel). 5
The 1M-token context window is the second differentiator. Nemotron 3 Ultra scores 94.7% on RULER at 1M tokens, the highest among all evaluated open models — DeepSeek V4 Pro hits 94.2% and Qwen-3.5 hits 90.1% at the same length. 5 FriendliAI's deployment team noted that the 1M window "eliminates the need to chunk large repos" for coding agents — a concrete operational simplification that also means fewer context-boundary errors. 6
Where it stands versus other open frontier models
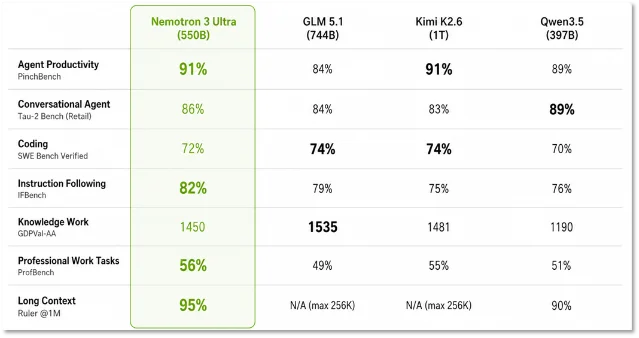
LMSYS benchmark comparison: Nemotron 3 Ultra (550B) vs. GLM 5.1 (744B), Kimi K2.6 (1T), Qwen3.5 (397B) across seven dimensions. 7
On the Artificial Analysis Intelligence Index, Nemotron 3 Ultra scores 47.7 (NVFP4) / 48.2 (BF16) — the highest US open-weights model, ahead of Gemma 4 31B (39.2) and Nemotron 3 Super (36.0). 3 The Chinese open frontier still leads on raw intelligence: Kimi K2.6 scores 53.9 on the same index. 8
On task-specific agentic benchmarks, the model is competitive but not uniformly leading. SWE-Bench Verified: 71.9% (vs. DeepSeek V4 Pro 74.0%, Kimi K2.6 69.5%). Terminal Bench 2.1: 56.4 (vs. Kimi K2.6 67.2). PinchBench (agent productivity): 90.0% — tied with Kimi K2.6. 5 Artificial Analysis summarizes the positioning accurately: Nemotron 3 Ultra "completes tasks at a much faster pace than peers due to its high inference speed while scoring competitively on the benchmark." 3 The bet is throughput-to-accuracy ratio, not top-of-leaderboard accuracy.
One production deployment is already public: CodeRabbit integrated Nemotron 3 Ultra for code review and measured review quality matching their previous frontier-model blend at ~50% lower latency. 9 That's a live production outcome, not a benchmark.
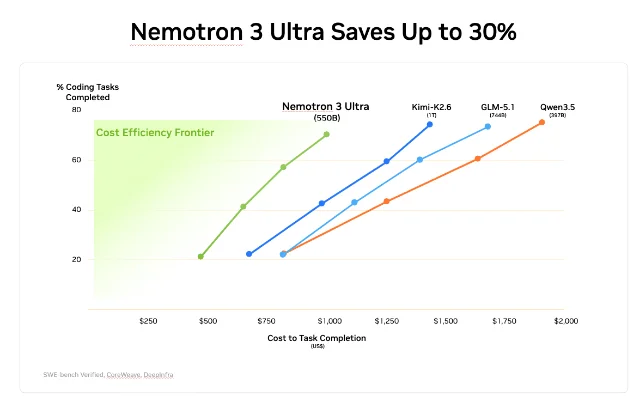
LMSYS cost-efficiency comparison on SWE-Bench Verified coding tasks. Nemotron 3 Ultra sits on the cost-efficiency frontier — completing more tasks per dollar than Kimi K2.6, GLM-5.1, or Qwen3.5. 7
Loading stats card…
The openness calculus
Nemotron 3 Ultra is released under the OpenMDW-1.1 license (Linux Foundation), which allows commercial use. 10 Four weight checkpoints are on HuggingFace: BF16 (8× B200 minimum), NVFP4 (4× B200 minimum), a base pretrained model, and a Generative Reward Model for RLHF pipelines. 5 Training data (226 datasets, 53.8 TiB) and training recipes are also open. 11
Day-0 inference support covers vLLM, SGLang, and TRT-LLM. 7 Via API, OpenRouter lists it at $0.50/M input tokens and $2.50/M output tokens. 12 The realistic hardware floor for self-hosting is 16× H100 or 8× H200 — squarely enterprise territory. For teams below that threshold, the managed API route is the practical path.
Early adopters span Perplexity, Palantir, CrowdStrike, ServiceNow, Harvey (legal AI), Glean, and CodeRabbit. 11
What this means for your roadmap
If you're building coding or research agents: Nemotron 3 Ultra is the first open US model where the speed-quality tradeoff is workable for production. The concrete implementation path: use Nemotron 3 Ultra as the orchestrator model — the one that plans, delegates subtasks, synthesizes results, and handles long-context reasoning across the full session. Route specialized single-turn calls (quick lookups, format transformations) to lighter models like Nemotron 3 Nano (a 30B total / 3B active MoE with 32K context) within the same family to control cost. 5 The 1M-token window means you can feed an entire codebase or document corpus directly without chunking logic.
If you're evaluating open vs. proprietary for your agent stack: The build-vs-buy equation has shifted. An open model at $2.50/M output tokens with 400 tokens/s throughput and 1M context changes what "good enough" means for latency-sensitive agent pipelines. One early cost-comparison by community tester Rahul Dahre estimated Nemotron 3 Ultra at roughly 10× cheaper than GPT-5.5 for similar quality tasks — though that figure is a single practitioner test and has not been independently verified. The official LMSYS cost-efficiency data on SWE-Bench Verified does confirm Nemotron 3 Ultra completes coding tasks at lower total cost than Kimi K2.6, GLM-5.1, and Qwen-3.5. 7
If the hybrid architecture pattern is new to you: Mamba (linear-complexity state-space model) + sparse Attention + MoE is becoming the standard recipe for frontier-scale open models — you saw the same logic in DeepSeek V4 Pro and Gemma 4. For product architecture decisions, this matters because Mamba-optimized serving stacks (SGLang's DP-Attention support, vLLM v0.22.0) are becoming the common deployment denominator. Infrastructure your team builds around this stack generalizes across the next generation of open models. 7
The watch item: Nemotron 3 Ultra's intelligence score (47.7) still sits 6 points below Kimi K2.6 (53.9) and well below proprietary frontier (Claude Opus 4.8 max at 61.4, GPT-5.5 at 60.2). 3 For tasks where reasoning depth is the ceiling — complex multi-hop research, advanced math, nuanced judgment calls — the proprietary models still hold the edge. Nemotron 3 Ultra wins where throughput and cost are the constraints. That covers more of the agentic product surface than PMs typically assume.

Add more perspectives or context around this Post.